
Gemma 4 12B : installer l’IA open source Google sur PC ou Mac
Gemma 4 12B est un modèle d’IA open source publié par Google le 3 juin 2026, conçu pour fonctionner sur des PC portables avec seulement 16 Go de VRAM ou de mémoire unifiée. Ce modèle est capable de traiter du texte, de l’image, de la vidéo et de l’audio avec une fenêtre de contexte de 256 000 jetons.
Utiliser une IA performante directement sur son ordinateur portable, sans transférer de données dans le cloud, c’est ce que promet le Gemma 4 12B, lancé le 3 juin 2026 par Google. Ce modèle, contrairement à d’autres plus volumineux de la gamme, est conçu pour tenir dans la mémoire d’un ordinateur portable, et son installation ne prend que deux minutes.
Pour rappel, un modèle open (ou open weight) est une IA dont les fichiers, appelés poids, peuvent être téléchargés. Vous les transférez sur votre disque dur et l’IA fonctionne en local, sans connexion Internet. Contrairement à Gemini ou ChatGPT, qui opèrent sur les serveurs de leurs sociétés et facturent l’utilisation.
Qu’est-ce que le 12B exactement ?
Le 12B est le cinquième membre de la famille Gemma 4, publié, comme les autres, sous la licence Apache 2.0.
En pratique, cette licence permet l’utilisation commerciale, la modification et la redistribution sans verser de royalties à Google, ce qui en fait l’une des plus flexibles du marché. Sa spécificité réside dans son nom complet, « 12B Unified ».
Alors que les autres modèles Gemma 4 utilisent des encodeurs dédiés pour le traitement des images ou du son, le 12B ne le fait pas. Pour la vision, il utilise un module léger qui gère l’analyse visuelle. Pour l’audio, c’est encore plus simplifié : il n’y a pas d’encodeur ; le signal sonore brut est directement intégré dans le même espace que les jetons de texte. Cela donne une architecture unique, réduisant la latence, économisant de la mémoire, et facilitant son exécution en local.
De plus, il est polyvalent : il traite du texte, des images, de la vidéo et de l’audio, avec une fenêtre de contexte de 256 000 jetons, ce qui permet d’ingérer de longs documents ou un dépôt de code en une seule fois. À noter qu’il s’agit du plus grand modèle Gemma 4 capable de traiter l’audio. Les 26B et 31B, quant à eux, se limitent au texte et à l’image. Si vous recherchez des fonctionnalités de transcription ou de traduction vocale en local, le 12B est votre meilleure option dans la gamme.
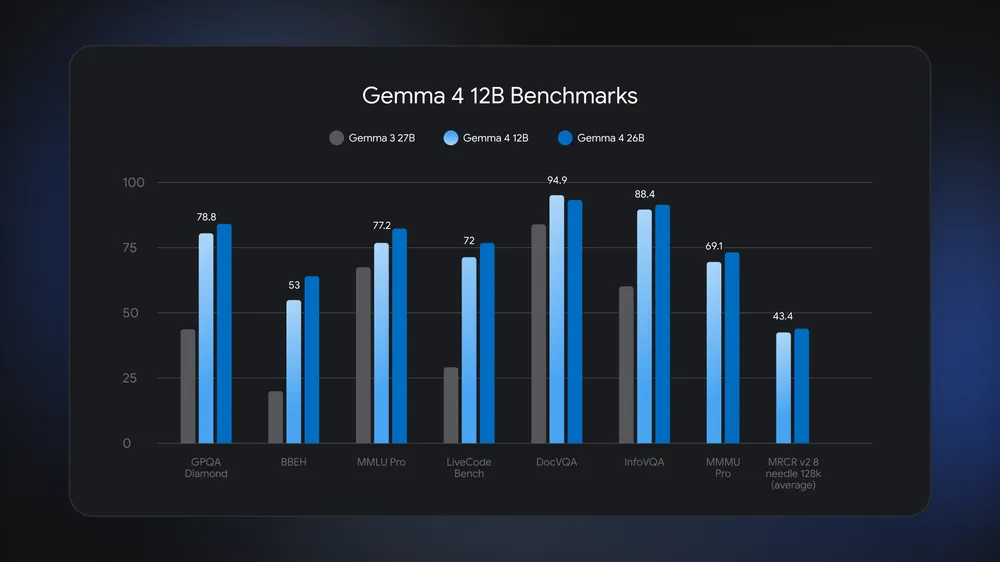
Le gain de performance est significatif. Selon InfoQ, Gemma 4 a presque doublé son score en raisonnement scientifique en une génération : sur le test GPQA Diamond, le 12B atteint 78,8 %, alors que le Gemma 3 27B de l’année précédente se contentait de 42,4 %. L’idée est de créer un modèle deux fois plus léger qui dépasse l’ancienne référence. Si le sujet de l’IA de Google vous intéresse plus largement, un guide complet sur Gemini est également disponible.
Pourquoi le 12B est le choix idéal pour un PC portable
C’est ici que tout se joue. Google présente ce modèle comme « laptop ready » : il fonctionne en local avec seulement 16 Go de VRAM ou de mémoire unifiée. De plus, il offre des performances très proches de celles du modèle 26B, qui est plus puissant, tout en ayant moins de la moitié de son empreinte mémoire. Autrement dit, vous profitez de la plupart des qualités du modèle supérieur sans nécessiter de matériel de type gamer ou de station de travail. C’est le nouvel équilibre entre qualité et mémoire, particulièrement adapté aux ordinateurs portables.
Sur Mac, l’avantage est encore plus marqué. Leur mémoire est unifiée, ce qui signifie que la RAM et la VRAM ne font qu’un, et un MacBook Air ou Pro avec 16 Go partage toute cette mémoire avec le modèle. Sur un PC portable, c’est la carte graphique (ou la mémoire système si aucune GPU dédiée n’est présente) qui s’en occupe. Dans les deux cas, 16 Go suffisent à faire fonctionner le 12B. Bien que cela soit complexe sur un PC portable, certains modèles sont maintenant équipés de mémoire unifiée.
Configuration requise et procédure d’installation
Le facteur clé, c’est la mémoire. Ce n’est pas tant le processeur ou la carte graphique, mais la quantité de RAM ou de VRAM (mémoire dédiée à la carte graphique) disponible. Règle simple : votre mémoire totale doit excéder la taille du fichier à télécharger. Sur Mac, la RAM et la VRAM étant unifiées, ça favorise les récents MacBook.
Voici les exigences de chaque variante, basées sur les recommandations de la communauté et des fichiers GGUF (le format compressé utilisé pour l’usage local).
| Modèle | Type | Mémoire conseillée | Pour quelle machine |
|---|---|---|---|
| E2B / E4B | Edge | ~3 à 4 Go | Smartphone, Raspberry Pi |
| 12B Unified | Dense | ~8 Go (Q4) | PC portable avec 16 Go unifiés/VRAM, MacBook Air/Pro avec au moins 16 Go |
| 26B A4B | MoE | ~14 Go (Q4) | GPU 16 Go, Mac 18 Go+ |
| 31B | Dense | ~18 Go (Q4) | RTX 3090/4090, Mac 24 Go+ |
À retenir : avec 16 Go de mémoire, le 12B en version 4 bits passe sans problème et garde de la marge pour le contexte. C’est le meilleur compromis entre qualité et mémoire pour un ordinateur portable. Si vous êtes limité à 8 Go, il vaut mieux opter pour une version quantifiée plus agressive du 12B ou choisir l’E4B, qui est plus modeste mais utilisable. Attention : ne tentez pas le 26B ou le 31B sur un simple PC portable de 16 Go, cela mènerait à des sorties incohérentes et à des pannes.
Pour aller plus loin
Comment installer un modèle LLM type ChatGPT sur PC ou Mac en local ? Voici le guide ultime pour tous
Pour l’installation, la méthode la plus simple est d’utiliser Ollama, une application qui gère le téléchargement et la mémoire toute seule. Installez la dernière version, puis une seule ligne dans le terminal : ollama run gemma4:12b.
Pour les Mac équipés de la puce Apple Silicon, MLX est le moteur natif le plus rapide. Les utilisateurs préférant une interface graphique choisiront LM Studio, tandis que les bricoleurs opteront pour llama.cpp pour des contrôles plus précis. Les poids peuvent être téléchargés depuis Hugging Face et Kaggle ; l’équipe d’Unsloth propose également des GGUF « Dynamic » optimisés qui permettent de faire fonctionner le 12B de manière plus efficace. Si vous souhaitez une méthode étape par étape, peu importe le système, notre guide sur l’installation d’un LLM en local détaille tout.
Utilisations possibles
Une fois configuré, le Gemma 4 12B excelle en raisonnement multi-étapes, génération de code, analyse d’images et de documents. Étant multimodal, vous pouvez lui fournir une capture d’écran d’un tableur ou d’une facture et lui demander de l’interpréter. De plus, grâce à sa compréhension de l’audio, il peut également transcrire, formater et traduire la voix, entièrement hors ligne : Google le démontre avec son application AI Edge Eloquent. Cela représente une capacité que les autres modèles Gemma 4, limités au texte et à l’image, ne possèdent pas. Il est également capable de gérer l’appel d’outils et de produire des sorties JSON structurées, en faisant ainsi un moteur crédible pour des agents autonomes maison.
L’avantage véritable, au-delà des performances : toutes les données restent sur votre machine. Pas de données envoyées à des tiers, pas de coût par requête, pas de limite de débit. Pour l’analyse de documents sensibles ou de code confidentiel, cela représente un atout majeur. Le chercheur Nathan Lambert résume bien le défi : le succès de Gemma 4 dépendra d’abord de sa facilité d’utilisation, davantage que de quelques éléments de benchmark. Et dans ce cadre, un modèle pouvant être utilisé sur un PC portable coche toutes les cases.
Si vous avez un ordinateur portable récent avec 16 Go de mémoire ou un MacBook avec mémoire unifiée, n’hésitez pas à tester le 12B : c’est l’IA locale la plus avancée actuellement pour un ordinateur portable, gratuite et sans attaches. Si votre machine est plus modeste ou si vous n’appréciez pas les lignes de commandes, restez sur l’E4B via Ollama ou LM Studio. Dans tous les cas, l’époque où l’IA utilisable nécessitait une connexion et un abonnement est désormais révolue.
Pour aller plus loin
Comment installer Google Gemma 4 sur votre smartphone Android ou iPhone : un « ChatGPT » gratuit et sans connexion