
Test du Nvidia DGX Spark: le mini PC IA de Dell avec 128 Go de RAM
En octobre 2025, Nvidia a annoncé le lancement de la machine DGX Spark, équipée de la puce GB10 Superchip, destinée aux professionnels du deep learning et au monde de la création assistée par IA. Le modèle Dell Pro Max, qui reprend la conception du DGX Spark, contient un SSD NVMe de 4 To et est dimensionné à 150 × 150 × 51 mm.
En octobre dernier, une machine intrigante a fait son apparition dans le catalogue du géant Nvidia. Bien que son boîtier soit à peine plus grand qu’un Mac mini, il renferme une quantité impressionnante de mémoire et ce que son créateur désigne comme un Superchip.
Pour aller plus loin
Qu’est-ce que cette mystérieuse carte mère Nvidia ? Nous vous l’expliquons.
Ciblant les professionnels du deep learning et le domaine de la création assistée par IA, cette machine annonce surtout une transformation dans l’utilisation de l’informatique au grand public.

Bien que ce marché reste encore un peu confidentiel, des ordinateurs ultra-compacts dotés de mémoire vive abondante et équipés de puces capables d’accélérer les applications locales d’intelligence artificielle commencent à émerger. Apple a lancé ce concept en 2022 avec ses Mac Studio, des stations de travail miniatures et puissantes destinées aux créateurs.
Dans le secteur des PC, AMD riposte avec sa gamme d’APU Ryzen AI Max, intégrée dans des ordinateurs portables professionnels et des mini-ordinateurs qui reprennent largement le concept du Mac Studio.
Il était donc logique que le leader des processeurs pour l’apprentissage profond propose sa propre version de ce concept. Annoncée en janvier 2025 sous le nom de projet DIGITS, cette machine a été lancée au dernier trimestre de l’année sous la forme du DGX Spark.
GB10 Superchip : un petit monstre sous le capot
Au cœur de cette machine atypique se trouve le GB10, un system on chip que la société de Santa Clara qualifie sans réserve de Superchip.
Avec ses dix cœurs haute performance ARM Cortex X925, ses dix cœurs à faible consommation Cortex A725 et un GPU intégrant quarante-huit Stream Multiprocessors, similaire au GB205 équipe de la RTX 5070, le GB10 se présente comme un véritable monstre. Bien qu’il ne rivalise pas avec les TDP très élevés des B200 utilisés dans les DGX SuperPod pour les datacenters d’IA, sa consommation en charge atteint tout de même 140 W. Ce qui est supérieur au M5 Max d’Apple et comparable à celle d’une carte graphique d’entrée de gamme, soulignant la volonté de Nvidia d’intégrer un maximum de puissance dans un format compact.

En deep learning, la mémoire vive est essentielle. Le DGX Spark est donc doté d’une RAM très généreuse de 128 Go de LPDDR5X, interfacée via un bus large de 256 bits avec le SoC de la machine.
Une des caractéristiques novatrices du Spark est son espace mémoire unifié, accessible en totalité tant par le CPU que par le GPU de la puce, ce qui supprime les restrictions imposées par les cartes graphiques classiques. Bien que celles-ci puissent être suffisamment puissantes pour des tâches d’inférence pour les individus, elles souffrent d’une quantité limitée de VRAM, ce qui empêche l’utilisation de réseaux neuronaux étant gourmands en mémoire ou d’exécuter plusieurs modèles simultanément.
Cependant, cette générosité a un revers : sur un bus 256 bits, la LPDDR5X du Spark est limitée à 273 Go/s de bande passante, bien en-deçà des ~800 Go/s qu’Apple propose sur ses variantes Ultra M-series depuis 2022, et des 1,8 To/s de la GDDR7 d’une RTX 5090. Cette limite pénalisera sans doute les performances en inférence des gros modèles de langage (LLM) à l’avenir.
Dell Pro Max : la version sobre du Spark
Le modèle que nous avons testé provient de Dell. Bien qu’il ne s’agisse pas du modèle présenté par Nvidia en octobre dernier, il en reprend tous les éléments : la carte mère très compacte embarquant le GB10 est logée dans un boîtier de quinze centimètres de côté pour cinq centimètres de haut.
Ce volume est presque exclusivement consacré au système de refroidissement, composé d’un large radiateur surmonté de deux ventilateurs à flux radial, qui, bonne nouvelle, restent assez discrets même en pleine charge.
Esthétiquement moins tape-à-l’œil que le modèle proposé par Nvidia, le design de ce Dell Pro Max est minimaliste, utilisant des teintes de noir et de gris foncé avec une façade en nid d’abeille.
Dell a équipé notre modèle d’un SSD NVMe de 4 To, un espace de stockage généreux qui se remplit rapidement lorsque l’on jongle avec de nombreux modèles neuronaux. L’intérêt du DGX Spark réside justement dans sa capacité à charger des modèles dépassant les 100 Go de mémoire, rendant ainsi le stockage précieux.
Fiche technique du Dell Pro Max avec GB10
| Détails | Caractéristiques |
|---|---|
| Puce | Nvidia GB10 Superchip (architecture Grace Blackwell) |
| CPU | 20 cœurs ARMv9.2 — 10× Cortex-X925 + 10× Cortex-A725 |
| GPU | Blackwell, 6 144 cœurs CUDA (équivalent RTX 5070) |
| Performance IA | 1 000 TFLOPS FP4 (1 pétaFLOP en sparse) |
| Mémoire | 128 Go LPDDR5X unifiée, bus 256 bits, 273 Go/s de bande passante |
| Stockage | SSD M.2 NVMe — 1 To, 2 To ou 4 To selon configuration (SED Ready) |
| Système | Nvidia DGX OS 7 (basé sur Ubuntu Linux) |
| Connectique | 4× USB-C Gen 2×2 (dont 1 dédié à l’alimentation, 3 avec DisplayPort Alt mode), 1× HDMI 2.1b, 1× RJ-45 10 GbE, ConnectX-7 Smart NIC avec 2× QSFP 200 Gbps |
| Sans-fil | Wi-Fi 7 (puce MediaTek MTK7925), Bluetooth |
| Sécurité | TPM 2.0 |
| Châssis | Dell L6, façade en nid d’abeille gris anthracite |
| Dimensions | 150 × 150 × 51 mm |
| Poids | 1,31 kg |
| Modèles d’IA supportés | Jusqu’à 200 milliards de paramètres en local (400 milliards en cluster de deux machines via QSFP) |
Côté connectiques, aucune surprise : elles sont identiques pour toutes les variantes du Spark qui utilisent cette carte mère.
Quatre ports USB-C dont un dédié à l’alimentation, un port HDMI, un port RJ45 10 Gbps et, bien sûr, deux ports QSFP 200 Gbps permettant de relier plusieurs machines entre elles (à partir de trois, un switch sera nécessaire) pour partager leurs espaces mémoire et charger des modèles d’IA encore plus volumineux. La présence d’une carte Wi-Fi équipée d’une puce MediaTek MT7925 compatible Wi-Fi 7, mais limitée à un canal de 160 MHz, est également à noter.
DGX OS : du Linux qui se fait oublier
La prise en main du Spark est rapide et les utilisateurs familiers avec les systèmes Linux retrouveront vite leurs repères avec DGX OS, qui se révèle être un Ubuntu personnalisé par Nvidia. L’application Nvidia Sync permet d’accéder rapidement au tableau de bord et au terminal de la machine depuis un ordinateur de bureau.
Bien qu’il soit possible de connecter la station à un écran et à un ensemble clavier/souris, ce n’est pas vraiment nécessaire : ce supercalculateur est conçu pour se faire oublier dans un coin de bureau et être géré depuis un PC, que ce soit via un terminal SSH ou via l’application dédiée (disponible pour Windows, Mac et Ubuntu).
L’installation est facilitée : lors du premier démarrage, la station diffuse un réseau Wi-Fi auquel l’utilisateur peut se connecter pour initialiser la configuration, les mises à jour et la création de profils.
Il est aussi possible de le faire au clavier et à la souris, mais gager que ce ne soit pas nécessaire pour cette machine, tant qu’on a un minimum de familiarité avec un terminal Linux.
À quoi sert vraiment cette machine ?
La question que beaucoup se posent est la suivante : quel est l’usage de cette machine ? La réponse est vaste.
Sa vocation principale est d’offrir aux développeurs spécialisés dans l’apprentissage profond la liberté de concevoir et de tester leurs applications d’IA, sans avoir besoin de la puissance d’un datacenter ni de dépendre de services en ligne, allant de la location de calcul GPU à des plateformes d’IA complètes. Le Spark s’intègre aussi parfaitement dans un environnement lié à l’écosystème Nvidia, où il agit comme un composant supplémentaire permettant de prototyper rapidement avant de déployer en production sur des SuperPod.
Cependant, l’utilisation de cette machine ne s’arrête pas là. Avec 128 Go de RAM, il devient possible de manipuler des réseaux de neurones suffisamment grands et performants pour envisager de ne plus faire appel aux services cloud des géants de la tech comme OpenAI, xAI, Microsoft ou Anthropic, entre autres. En gros, tout ce qui peut être réalisé en ligne via des plateformes payantes peut être reproduit localement sur le DGX Spark. Chatbots, génération et modification d’images, création de vidéos, agents autonomes, gestion de flux de travail, les usages sont multiples.
On touche ici à la plus grande force du concept : être totalement autonome et avoir la liberté d’utiliser les services d’IA déployés soi-même.
Dans un monde où la souveraineté numérique et la confidentialité des données sont devenues des enjeux cruciaux tant pour les États que pour les citoyens, disposer d’une machine permettant de bénéficier de la puissance de l’IA tout en préservant ses données et sa vie privée est un luxe inestimable. Les services hébergés localement nous protègent également des surprises désagréables, telles que les changements d’abonnements ou la suppression soudaine de certaines fonctionnalités par les grandes plateformes.
Un chatbot maison, sans dépendre d’OpenAI
La première chose que l’on peut tester sur cette machine est un agent conversationnel ; les chatbots sont les applications d’IA les plus emblématiques pour le grand public.
Nvidia fournit toute la documentation nécessaire pour les utilisateurs, mais les utilisateurs avancés peuvent utiliser les dépôts Git, les containers Docker libres ou ceux du catalogue de microservices proposés par Nvidia (les NIM).
Notons que le système d’exploitation personnalisé par le constructeur inclut tous les pilotes et bibliothèques CUDA nécessaires pour déployer rapidement des applications GPU. Il n’est plus nécessaire de passer des heures à rechercher les bonnes dépendances et à configurer les chemins des bibliothèques. Télécharger les images Docker d’Ollama et OpenWebUI accélérées CUDA ne prend que quelques minutes, rendant possible le déploiement d’un chatbot opérationnel.
Bien que l’installation d’une telle application n’ait rien de compliqué sur un système équipé d’un GPU récents, la véritable force du DGX Spark réside dans sa capacité à manipuler de gros modèles dont la pertinence n’a rien à voir avec celle des petits réseaux tenant dans la mémoire d’une carte graphique classique. Qwen3.5-122B-A10B, un modèle multimodal large, semble être un bon candidat pour ce test : malgré ses 85 Go de mémoire, son architecture mixture of experts avec dix milliards de paramètres activés par token devrait permettre au GB10 de fonctionner suffisamment vite pour un usage personnel.
On met donc notre agent en action avec le développement d’un petit projet : une application qui résume automatiquement les vidéos d’une chaîne YouTube pour les publier sur un canal Discord. Qwen3.5 construit rapidement une architecture à la fois simple et robuste pour répondre à notre besoin et produit les scripts Python associés.
Nous aurions pu pousser l’intégration à permettre au LLM d’exécuter et de vérifier lui-même son code à l’aide d’agents comme OpenHands ou Hermes, mais nous n’en avons même pas ressenti le besoin.
La vitesse d’inférence du GB10 sur un tel modèle, alliée à la longueur de la conversation dépassant les soixante-cinq mille tokens, fait que les réponses de notre chatbot prennent parfois jusqu’à trois minutes – de l’évaluation du prompt à la sortie finale, avec une phase de réflexion.
Néanmoins, notre projet prend vie en une après-midi : notre bot, propulsé par Ollama et Scriberr et orchestré par n8n, est opérationnel et ne manque plus aucune vidéo de notre chaîne préférée.
Il n’est pas nécessaire d’investir dans une machine à plus de six mille euros pour réaliser ce type d’application, mais il est essentiel de rappeler que tout est effectué en local, sans que l’information ne quitte notre réseau, et sans dépendre de limites ou de fonctionnalités imposées par une plateforme cloud. La machine est utilisée librement, ce qui en fait sa force.
Génération d’images locale avec Krita et ComfyUI
De nombreuses applications open source commencent maintenant à intégrer des fonctionnalités d’IA locale pour remplacer les écosystèmes payants et propriétaires.
Pour aller plus loin
Comment installer un modèle LLM, type ChatGPT, sur PC ou Mac en local ? Voici le guide ultime pour tous.
C’est par exemple le cas de Krita, une alternative gratuite au célèbre Photoshop d’Adobe, qui comprend un plug-in permettant de relier le logiciel à un serveur ComfyUI, une application très connue dans le domaine de l’IA libre, qui offre une multitude de modèles d’IA générative. Nous avons installé ComfyUI depuis la page GitHub du projet et configuré le plug-in Krita pour se connecter à notre instance locale.
La mémoire abondante fournie par le Spark permet d’accéder directement à Qwen-Image, l’un des générateurs d’images les plus efficaces disponibles en open weight.
Nous pouvons maintenant générer, éditer et améliorer des assets graphiques à volonté grâce à la puissance de l’IA, sans dépendre des quotas d’utilisation d’un service externe et, surtout, sans qu’un seul pixel ne quitte notre environnement.
Fine-tuning : entraîner ses propres modèles à la maison
Le DGX Spark n’est cependant pas uniquement conçu pour l’inférence : il est principalement optimisé pour l’entraînement de modèles complexes, parfois impossibles à charger dans la mémoire d’une carte graphique, même très haut de gamme.
Le fine-tuning fait partie des nombreuses utilisations de cette machine et, avec des outils comme Llama-Factory ou AI-Toolkit, il est facile d’entraîner un réseau neuronal sur un jeu de données spécifique. Nous avons utilisé le petit ensemble de données fourni par Nvidia pour entraîner Flux.1 Dev à reproduire fidèlement une version « jouet » du big boss de la société.
L’entraînement d’un Low Rank Adapter, un fichier agissant comme une sorte de couche additionnelle pour le modèle de base, prend environ trois heures sur le DGX Spark pour obtenir un résultat satisfaisant. Une GeForce RTX avec au moins 24 Go de VRAM aurait pu accomplir cette tâche de manière significativement plus rapide, mais avec une consommation d’énergie plus élevée et un temps consacré à régler l’outil pour faire tenir le modèle en mémoire.
Avec le Spark, on ne se préoccupe plus de ces questions : on lance l’entraînement et on récupère un LoRA qui peut être réutilisé avec des modèles quantifiés et qui peuvent fonctionner sur un GPU grand public.
Pour les développeurs et créateurs, bénéficier d’une telle capacité est un véritable atout.
Performances : ne pas se tromper de cible
Il est important de souligner que le DGX Spark n’est pas un serveur d’inférence. Certains pourraient le considérer comme une solution économique d’entreprise pour fournir des modèles à leurs clients. Toutefois, même si le GB10 est véritablement impressionnant pour un SoC dédié à l’IA, ses performances restent relativement limitées.
Il est exclu de fournir un LLM volumineux à plusieurs utilisateurs simultanément. L’inférence de Qwen3.5-122B-A10B, malgré son architecture mixture of experts n’activant que dix milliards de paramètres par token, peine à dépasser les 20 tokens/s. C’est également la vitesse que l’on obtient avec Qwen3.5-14B, qui peut cependant tenir dans la mémoire d’une carte graphique grand public, plus rapide, à condition d’utiliser une version quantifiée.
Les performances en inférence d’un LLM dépendent largement de la bande passante mémoire fournie par la LPDDR5X du Spark, qui ne peut pas vraiment rivaliser avec celle de la GDDR7 des dernières GeForce Blackwell. Dans ce domaine, une GeForce RTX 5060 Ti 16 Go, cette référence intéressante pour un novice souhaitant découvrir l’IA locale avec de petits réseaux sans débourser une fortune, est presque deux fois plus rapide.
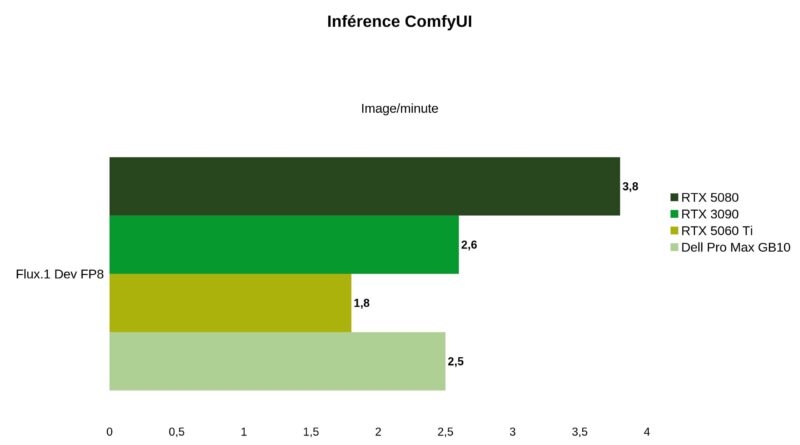
Le GB10 est en revanche plus performant avec des modèles de diffusion comme Flux.1 Dev FP8, où ses capacités d’inférence surpassent nettement celles de la RTX 5060 Ti, se rapprochant des performances d’une RTX 3090, un ancien haut de gamme Ampère, notablement plus bruyante et énergivore.
Dans l’ensemble, les performances du GB10 sont adéquates pour le prototypage d’un projet ou la création de contenu, mais il est crucial de garder à l’esprit que cette machine n’est pas destinée à être intégrée dans un environnement de production.
Prix et disponibilité
Ce mini PC Nvidia x Dell est proposé à plus de 7 000 euros dans cette configuration haut de gamme.
Il est à noter que ce même design de référence est disponible chez plusieurs autres fabricants partenaires de Nvidia, tels qu’Asus (Ascent GX10), Lenovo (ThinkStation PGX), HP, Gigabyte (AI Top Atom) ou MSI (EdgeXpert). Tous ces mini-PC partagent une base technique similaire et se distinguent principalement par leur design, leur capacité de stockage et leur prix.