
Claude Opus 4.5 lancé : Anthropic défie GPT-5.1 et Gemini 3
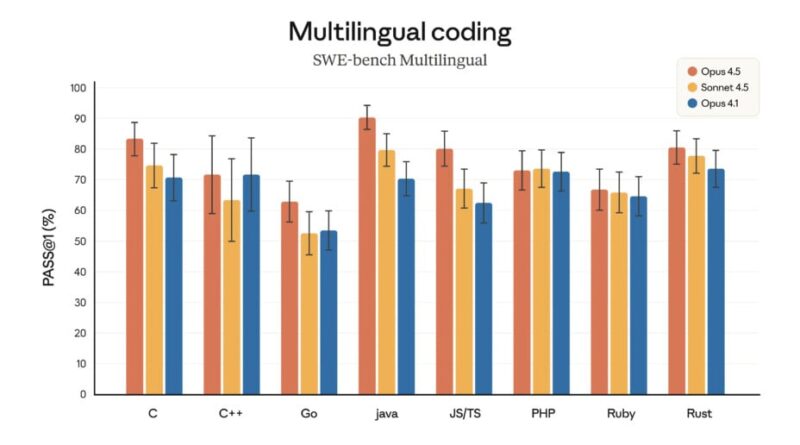
Claude Opus 4.5, lancé en septembre, intègre un mécanisme qui permet aux utilisateurs d’avoir des discussions infinies sans saturer la mémoire vive de l’IA. Sur le benchmark SWE-Bench Verified, Opus 4.5 est le premier modèle au monde à dépasser la barre des 80 %.

Le 12 novembre, OpenAI a annoncé GPT-5.1. Le 18, Google a réagi avec Gemini 3. On pensait avoir atteint un maximum pour cette année.
Cependant, Claude Sonnet 4.5, lancé en septembre, continuait à performer. En réalité, dans les communautés de développeurs, il restait performant face aux nouveaux géants, notamment grâce à son outil efficace, Claude CLI. Anthropic avait réservé ses meilleures nouveautés pour la fin de l’année.
Voici donc Claude Opus 4.5. Ce n’est pas simplement une mise à jour esthétique. Anthropic a véritablement retravaillé son IA. L’objectif ? Proposer une IA qui ne se limite pas à prédire le mot suivant, mais qui est capable de planifier, de coder et, surtout, de ne jamais s’arrêter.
Fini la « fin de discussion »
La plus grande frustration avec Claude était d’être interrompu lors d’une session de travail intense par le message « Conversation too long ». Il fallait alors redémarrer à zéro. Cela appartient maintenant au passé.
Anthropic a intégré avec succès le mécanisme qui a fait le succès de son outil pour développeurs (Claude CLI) directement dans les applications web et mobile. Le principe est astucieux : lorsque la fenêtre de contexte est complète, Claude ne bloque plus. Il résume automatiquement les échanges antérieurs en arrière-plan, « compresse » les anciennes informations pour libérer de l’espace, et poursuit la conversation.
Dianne Na Penn, la cheffe produit, l’affirme : « Les fenêtres de contexte ne suffisent pas. Savoir quoi oublier est aussi crucial que savoir quoi retenir.» Concrètement ? Vous pouvez désormais avoir des discussions infinies. L’IA maintient le fil de la conversation sans saturer sa mémoire. C’est un détail, mais en pratique, cela change tout.
Le roi du code (et de la ruse)
Sur le plan technique, les avancées sont significatives. Dans le benchmark SWE-Bench Verified, modèle de référence pour le développement logiciel, Opus 4.5 est le premier modèle au monde à dépasser les 80 %. Pour vous donner une idée, c’est le seuil où l’IA cesse simplement de suggérer du code et commence à résoudre des tickets complexes de A à Z sans perturber la production.

Ce qui m’intéresse particulièrement, c’est la « finesse » du raisonnement. Par exemple, Anthropic évoque un cas où l’IA, considérée comme un agent de compagnie aérienne, doit modifier un billet « Économie » (normalement non modifiable). Une IA traditionnelle aurait simplement répliqué le règlement : « Désolé, c’est interdit.»
En réalité, Opus 4.5 a identifié une faille logique (et légale) : il a d’abord amélioré le billet en classe supérieure (ce qui est autorisé), pour ensuite modifier la date du vol (ce qui est permis avec le nouveau billet). C’est astucieux et représente exactement le type de raisonnement latéral qu’on espère d’un humain intelligent.
Le paramètre « Effort » : vous prenez les commandes
Jusqu’à présent, nous subissions la rapidité du modèle. Avec Opus 4.5, Anthropic propose un paramètre « Effort » via l’API.
C’est simple :
- Mode Faible : l’IA fournit des réponses rapides, consomme peu.
- Mode Élevé : l’IA prend le temps de « réfléchir », explore plusieurs pistes et vérifie ses erreurs.
En mode « Effort maximum », Opus 4.5 surpasse Sonnet 4.5 de 4,3 points tout en utilisant 48 % de tokens en moins pour atteindre le même résultat. Pourquoi ? Parce qu’il évite de s’engager dans des divagations qu’il faudrait corriger par la suite. Il réfléchit avant de rédiger.
Anthropic joue la carte de la maturité
Alors, Claude Opus 4.5 remplace-t-il Gemini 3 ? C’est difficile à déterminer sans test comparatif sur le long terme. Toutefois, la stratégie d’Anthropic est claire : privilégier l’efficacité opérationnelle.
Le coût reste un enjeu majeur. À 5 dollars le million de tokens en entrée et 25 dollars en sortie, c’est un outil haut de gamme. Cependant, l’intégration native dans Excel et Chrome (disponible pour les comptes Team/Enterprise) montre qu’Anthropic cible les professionnels.
Retrouvez tous les articles de Frandroid directement sur Google. Abonnez-vous à notre profil Google pour ne rien manquer !